
曾有几家设备厂商提出各自解决方案,但都有一些缺陷。后经多次讨论,ITU-T(国际电信联盟远程通信标准化组)于今年2月制订了关于以太网单环网络的保护切换方案,即G.8032标准。下面介绍一下该标准的基本内容,但为了展示其优点,先介绍一下IETF(互联网工程任务组)于2003年发布的具有较大影响的以太网自动保护切换方案RFC3619。
一、RFC3619
该方案的实现过程如下:
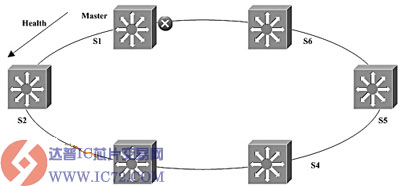
图1是由6台交换机构成的环网。首先,选择一台交换机,例如S1,作为主控节点。在环上各链路均正常的情况下,S1将它的一个端口阻塞,以防止逻辑成环而产生网络风暴。S1如何判断环路是完好的呢?它定时(比如每隔1秒)从一个端口向外发送检测帧,该帧经过环上节点逐个传递。如果该检测帧能从S1的另一个端口回来,S1认为环路是完好的。
当环上某条链路发生故障,例如S3和S4之间的链路发生故障时,S3和S4先把自己与故障链路相连的端口阻塞,然后向主控节点S1发送Link-down类型的消息,告诉它有链路故障。主控节点收到通知后,把它的后备端口打开,发送类型为Flush-down的消息给环上所有节点,告诉它们:环上有链路故障,请刷新地址转发表,如图2所示。这就实现了网络的快速保护切换。
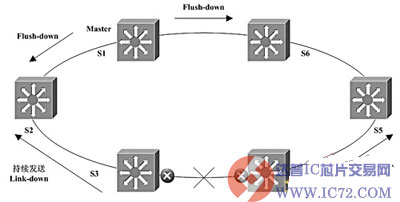
在实际环境中,Link-down消息在向主控节点传送的过程中有可能丢失。但是,因为主控节点在定期发送检测帧,所以,即使Link-down消息丢失,主控节点也可以根据收不到检测帧这一点来判断环路出现了故障。不过这种判断方法的反应速度显然比较慢。需要说明的是,环路出现故障后,S1仍继续定期发送检测帧。
当S3和S4之间的链路恢复正常时,检测帧得以穿过,主控节点S1发现检测帧成功返回,于是认为环路恢复正常,便再次阻塞其后备端口,并发送类型为Flush-up的消息给环上所有节点,告诉它们:环上链路恢复正常,请刷新地址。
仔细分析一下上述环网保护方法,不难看出它有以下几个弱点:
1.如果Link-down消息在送往主控节点的途中因故丢失,则主控节点只能依赖检测帧超时未返回来判断环路出现故障,而这个超时时间一般很长。例如,假设检测帧是每隔1秒钟发送一个,主控节点考虑到个别帧意外丢失的可能,通常需要将其返回的超时时间设定为2秒或3秒以上。这显然达不到快速切换的目的。
2.若链路故障是单向的,检测帧超时机制可能检测不到该故障。举个例子,假设S3和S4之间的那条链路出现的是S4→S3的单向故障(S3→S4是正常的),那么,逆时针方向传递的检测帧仍然能够顺利地在环上传递,S1无法据此判断环路故障,而只能根据Link-down消息来判断了。
二、G.8032标准
鉴于RFC3619存在上述弱点,有几家通信设备厂商曾向ITU-T提交了自己的方案,但都存在一些缺陷。经过多次讨论,ITU-T于2008年2月制订了G.8032标准。该标准与RFC3619存在明显不同,主要区别如下:
1.不发送检测帧。
2.链路发生故障后,发生故障的链路两端的节点开始定期反复发送Link-down消息,以避免消息丢失。发送Link-down消息的时间间隔不是均匀的,它有个特点:开始的三个Link-down消息时间间隔很短,短至毫秒级,后面的Link-down消息则以秒级的间隔较慢地发送。显然,这很好地解决了快速切换和减轻网络负担之间的矛盾。
3.链路恢复正常后,该链路相邻的两个节点也开始定期反复发送链路恢复的Link-down消息给主控节点。但是,主控节点在收到该消息后并不能立即断定整个环路恢复正常,而必须等待一段时间,看是否有消息到来。如果没有Link-down消息到来,则可断定环路恢复正常。这是考虑到环上可能出现两处链路故障的情形。我们假设S3和S4之间链路发生故障,S3和S4将反复发送Link-down消息给主控节点,如果S4和S5之间的链路也发生故障,则S5也将反复发送Link-down消息。若S3和S4之间的链路忽然恢复了,主控节点将收到S3发来的链路恢复的消息,但它不能立即断定环路恢复,而必须等待一小段时间,在这段时间里,S1将收到S5发来的Link-down消息,于是认为环路并未恢复正常。
以上的讨论仅针对单环网络而言。在实际应用中,以太网络经常出现多个环相交、相切等情况。对于多环网络,如何做到既能实现链路出现故障时进行快速切换,又避免逻辑成环,是一个复杂的问题。目前,中兴通讯、诺基亚西门子等少数厂商向ITU-T提出了自己的方案。但是,何时能集各家所长,形成完善统一的标准,尚未可知。限于篇幅,本文不对多环网络进行讨论。
